Training and evaluation
Last updated on 2026-06-30 | Edit this page
Estimated time: 60 minutes
Overview
Questions
- How is a neural network trained to make better predictions?
- What do training loss and accuracy tell us?
- How do we evaluate a model’s performance on unseen data?
Objectives
- Compile a neural network with a suitable loss function and optimizer.
- Train a convolutional neural network using batches of data.
- Monitor model performance during training using training and validation loss and accuracy.
- Evaluate a trained model on a held-out test set.
Compile and train your model
Now that we’ve defined the architecture of our neural network, the next step is to compile and train it.
What does “compiling” a model mean?
In PyTorch, we don’t “compile” a model in the same way as Keras. Instead, we explicitly define:
- A loss function, which measures the difference between the model’s predictions and the actual labels.
- An optimizer, such as gradient descent, which adjusts the model’s internal weights to minimize the loss.
- Metrics, such as accuracy, which we calculate manually during the training loop.
What happens during training?
Training is the process of finding the best set of weights to minimize the loss. This is done by:
- Making predictions on a batch of training data.
- Comparing those predictions to the true labels using the loss function.
- Adjusting the weights to reduce the error, using the optimizer.
What are batch size, steps per epoch, and epochs?
- Batch size is the number of training examples processed together
before updating the model’s weights.
- Smaller batch sizes use less memory and may generalize better but take longer to train.
- Larger batch sizes make faster progress per step but may require more memory and can sometimes overfit.
- Steps per epoch defines how many batches the model processes in one
epoch. A typical setting is:
steps_per_epoch = len(dataset_train) // batch_size - Epochs refers to how many times the model sees the entire training dataset.
Choosing these parameters is a tradeoff between speed, memory usage, and performance. You can experiment to find values that work best for your data and hardware.
PYTHON
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# Define the loss function and optimizer
# BCEWithLogitsLoss is used for binary classification
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters())
# Prepare data loaders
train_ds = TensorDataset(torch.tensor(dataset_train, dtype=torch.float32), torch.tensor(labels_train, dtype=torch.float32))
val_ds = TensorDataset(torch.tensor(dataset_val, dtype=torch.float32), torch.tensor(labels_val, dtype=torch.float32))
train_loader = DataLoader(train_ds, batch_size=16, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=16)
# Training parameters
epochs = 10
best_val_loss = float('inf')
# Start the timer
start_time = time.time()
# Training loop
train_losses, val_losses = [], []
train_accs, val_accs = [], []
for epoch in range(epochs):
model.train()
running_loss, correct, total = 0.0, 0, 0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs).squeeze()
loss = criterion(outputs, labels.squeeze())
loss.backward()
optimizer.step()
running_loss += loss.item()
predicted = (outputs > 0.5).float()
correct += (predicted == labels.squeeze()).sum().item()
total += labels.size(0)
epoch_loss = running_loss / len(train_loader)
epoch_acc = correct / total
train_losses.append(epoch_loss)
train_accs.append(epoch_acc)
# Validation
model.eval()
val_running_loss, val_correct, val_total = 0.0, 0, 0
with torch.no_grad():
for inputs, labels in val_loader:
outputs = model(inputs).squeeze()
loss = criterion(outputs, labels.squeeze())
val_running_loss += loss.item()
predicted = (outputs > 0.5).float()
val_correct += (predicted == labels.squeeze()).sum().item()
val_total += labels.size(0)
val_loss = val_running_loss / len(val_loader)
val_acc = val_correct / val_total
val_losses.append(val_loss)
val_accs.append(val_acc)
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), 'best_model.pt')
print(f"Epoch {epoch+1}/{epochs} - loss: {epoch_loss:.3f} - acc: {epoch_acc:.3f} - val_loss: {val_loss:.3f} - val_acc: {val_acc:.3f}")
# End the timer
end_time = time.time()
elapsed_time = end_time - start_time
print(f"Training completed in {elapsed_time:.2f} seconds.")We can now plot the results of the training. “Loss” should drop over successive epochs and accuracy should increase.
PYTHON
plt.plot(train_losses, 'b-', label='train loss')
plt.plot(val_losses, 'r-', label='val loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(loc='lower right')
plt.show()
plt.plot(train_accs, 'b-', label='train accuracy')
plt.plot(val_accs, 'r-', label='val accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(loc='lower right')
plt.show()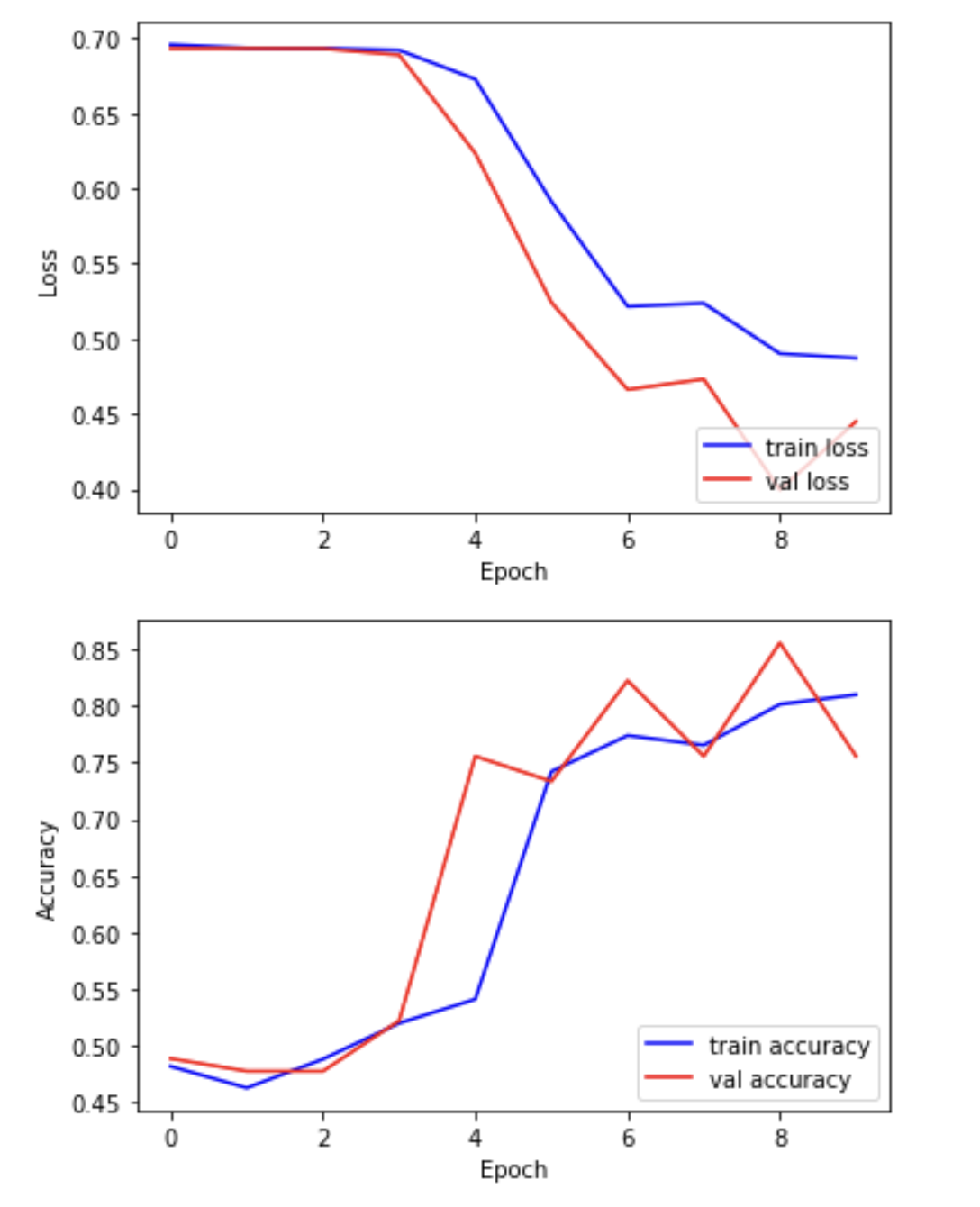
Exercise
Examine the training and validation curves.
- What does it mean if the training loss continues to decrease, but
the validation loss starts increasing?
- Suggest two actions you could take to reduce overfitting in this
situation.
- Bonus: Try increasing the dropout rate in your model. What happens to the validation accuracy?
If the training loss decreases while the validation loss increases, the model is overfitting — it’s learning the training data too well and struggling to generalize to unseen data.
You could:
- Increase regularization (e.g. by raising the dropout rate)
- Add more training data
- Use data augmentation
- Simplify the model to reduce capacity
- Increasing dropout may lower performance slightly but improve generalization. Always compare the training and validation accuracy/loss to decide.
Batch normalization
Batch normalization is a technique that standardizes the output of a layer across each training batch. This helps stabilize and speed up training.
It works by:
- Subtracting the batch mean
- Dividing by the batch standard deviation
- Applying a learnable scale and shift
You typically insert BatchNormalization() after a
convolutional or dense layer, and before the activation function:
Benefits can include:
- Faster training
- Reduced sensitivity to weight initialization
- Helps prevent overfitting
Challenge
- Try inserting a BatchNormalization() layer after the first convolutional layer in your model, and re-run the training. Compare:
- Training time
- Accuracy
- Validation performance
What changes do you notice?
- Adding batch normalization can improve training stability and accuracy. Find this line in your model:
Split it into two lines, and insert BatchNormalization()
before the activation:
PYTHON
x = nn.Conv2d(1, 8, kernel_size=3, padding=1)(inputs)
x = nn.BatchNorm2d(8)(x)
x = nn.ReLU()(x)You may notice:
- Smoother training curves
- Higher validation accuracy
- Slightly faster convergence
Remember to retrain your model after making this change.
Choosing and modifying the architecture
There is no single “correct” architecture for a neural network. The best design depends on your data, task, and computational constraints. Here is a systematic approach to designing and improving your model architecture:
Start simple
Begin with a basic model and verify that it can learn from your data. It is better to get a simple model working than to over-complicate things early.
Use proven patterns
Borrow ideas from successful models:
- LeNet-5: good for small grayscale images.
- VGG: uses repeated 3×3 convolutions and pooling.
- ResNet or DenseNet: useful for deep networks with skip connections.
Tune hyperparameters systematically
To improve performance in a structured way, try:
- Manual tuning: Change one variable at a time (e.g., number of filters, dropout rate) and observe its effect on validation performance.
- Grid search: Define a grid of parameters (e.g., filter sizes, learning rates, dropout values) and test all combinations. This is slow but thorough.
- Automated tuning: Use tools like Optuna to automate the search for the best architecture.
Evaluating your model on the held-out test set
In this step, we present the unseen test dataset to our trained network and evaluate the performance.
PYTHON
# Load the best model saved during training
model = ChestXRayNet()
model.load_state_dict(torch.load('best_model.pt'))
model.eval()
print('\nNeural network weights updated to the best epoch.')Now that we’ve loaded the best model, we can evaluate the accuracy on our test data.
PYTHON
# Evaluate the accuracy on our test data
model.eval()
with torch.no_grad():
test_ds = TensorDataset(torch.tensor(dataset_test, dtype=torch.float32), torch.tensor(labels_test, dtype=torch.float32))
test_loader = DataLoader(test_ds, batch_size=16)
correct, total = 0, 0
for inputs, labels in test_loader:
outputs = model(inputs).squeeze()
predicted = (outputs > 0.5).float()
correct += (predicted == labels.squeeze()).sum().item()
total += labels.size(0)
print(f"Accuracy in test group: {correct / total:.2f}")OUTPUT
Accuracy in test group: 0.80- Neural networks are trained by adjusting weights to minimize a loss function using optimization algorithms like Adam.
- Training is done in batches over multiple epochs to gradually improve performance.
- Validation data helps detect overfitting and track generalization during training.
- The best model can be selected by monitoring validation loss and saved for future use.
- Final performance should be evaluated on a separate test set that the model has not seen during training.